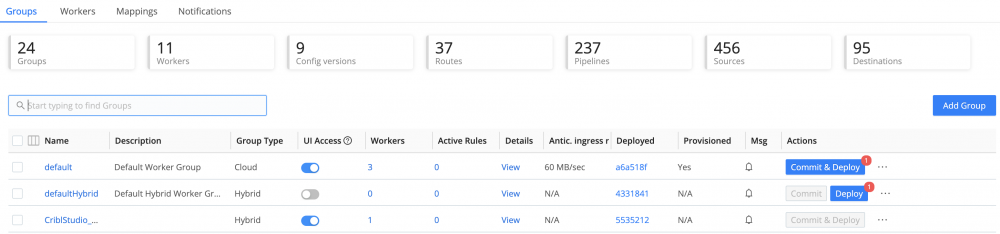
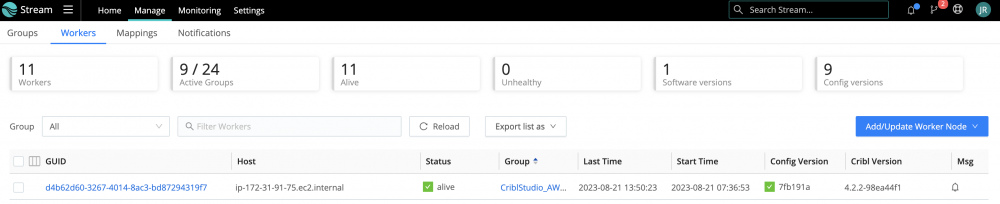
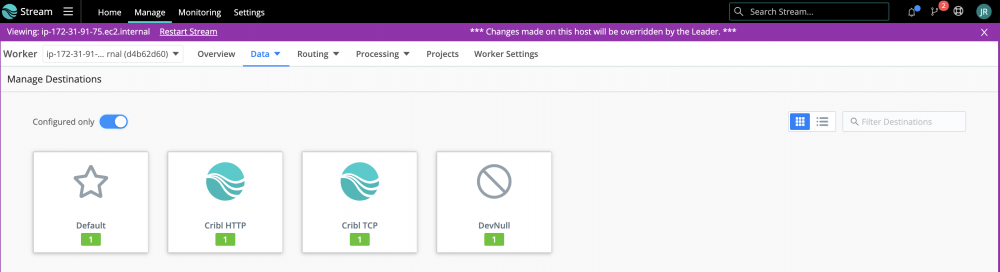
I can't get any of the data destinations to work. I have tried this with ElasticSearch, AWS S3 and Splunk. The message I get when I try a Test payload is "Error: 400-Bad Request Output … does not exist!"
The logs don't have any information either.
I'm running stream in a docker container. I got the same results on Cribl cloud instance as well.